EMNLP 2022
保护大型语言模型免受隐私泄露的影响在其在现实世界产品中广泛应用时变得越来越重要。然而,将可证明具有隐私保证的差分隐私(DP)应用于这些模型仍然具有挑战性,因为模型效用和隐私损失之间存在权衡。利用语言数据中敏感信息往往是稀疏的这一事实,Shi等人(2021年)形式化了一种名为选择性差分隐私(SDP)的DP概念扩展,以保护仅由策略函数定义的敏感标记。然而,他们的算法只适用于基于RNN的模型。本文提出了一个新颖框架Just Fine-tune Twice (JFT),可以实现最先进的基于Transformer的大型模型(指GPT2)对SDP进行处理。我们方法易于实施:首先使用经过删除敏感信息后域内数据对模型进行微调,然后再次使用原始域内数据通过private training 机制进行微调。此外,我们研究了策略函数不完善的情况,即错过敏感标记,并开发了系统化的方法来处理这种情况。实验证明与之前基准相比,我们方法能够取得较强效用。我们还通过金丝雀插入攻击对SDP隐私保证进行了实证分析。
随着自然语言处理(NLP)的快速发展,保护NLP模型免受泄露隐私信息的重要性日益增加。先前的研究尝试通过在这些模型上应用差分隐私(DP,Dwork等人,2014)来解决这一挑战(McMahan等人,2018;Li等人,2021)。然而,现有的DP学习算法存在用户控制有限和效用低下的问题,因为它们保护每个训练示例的全部内容(例如完整句子),而不考虑用户对隐私偏好,并且当只有训练示例中的部分信息是敏感时往往过于悲观。这个问题在NLP领域特别相关,因为NLP训练数据通常与稀疏领域相关的私密信息混合在一起,并且并非所有标记都需要得到保护。例如,在句子“我的社会安全号码是123-45-6789”中,只需保护实际社会安全号码的最后几个标记即可。
事实上,DP的定义并不妨碍我们仅保护数据中的敏感部分。具体而言,DP确保数据分析算法的输出在相邻数据集之间基本保持一致,同时提供了根据特定应用环境调整相邻关系定义的灵活性。Shi等人(2021年)最近提出了DP的一个实例化方法,称为Selective-DP(SDP),它将相邻数据集定义为仅在训练示例的敏感部分有所差异,并且因此SDP只选择隐藏敏感部分的差异。SDP特别适用于NLP和其他非结构化、高维度数据,在这些数据中,敏感信息只占很小一部分。但是他们用于实现SDP的隐私机制存在三个问题:1)需要对模型有大量知识才能区分私有变量和公共变量,并且不清楚他们针对循环神经网络设计的算法如何扩展到现代基于Transformer架构的NLP模型;2)它只评估了显式私有实体而没有考虑上下文敏感信息;3)它不能保护未检测到的敏感标记;这些限制限制了SDP在真实场景中的适用性。
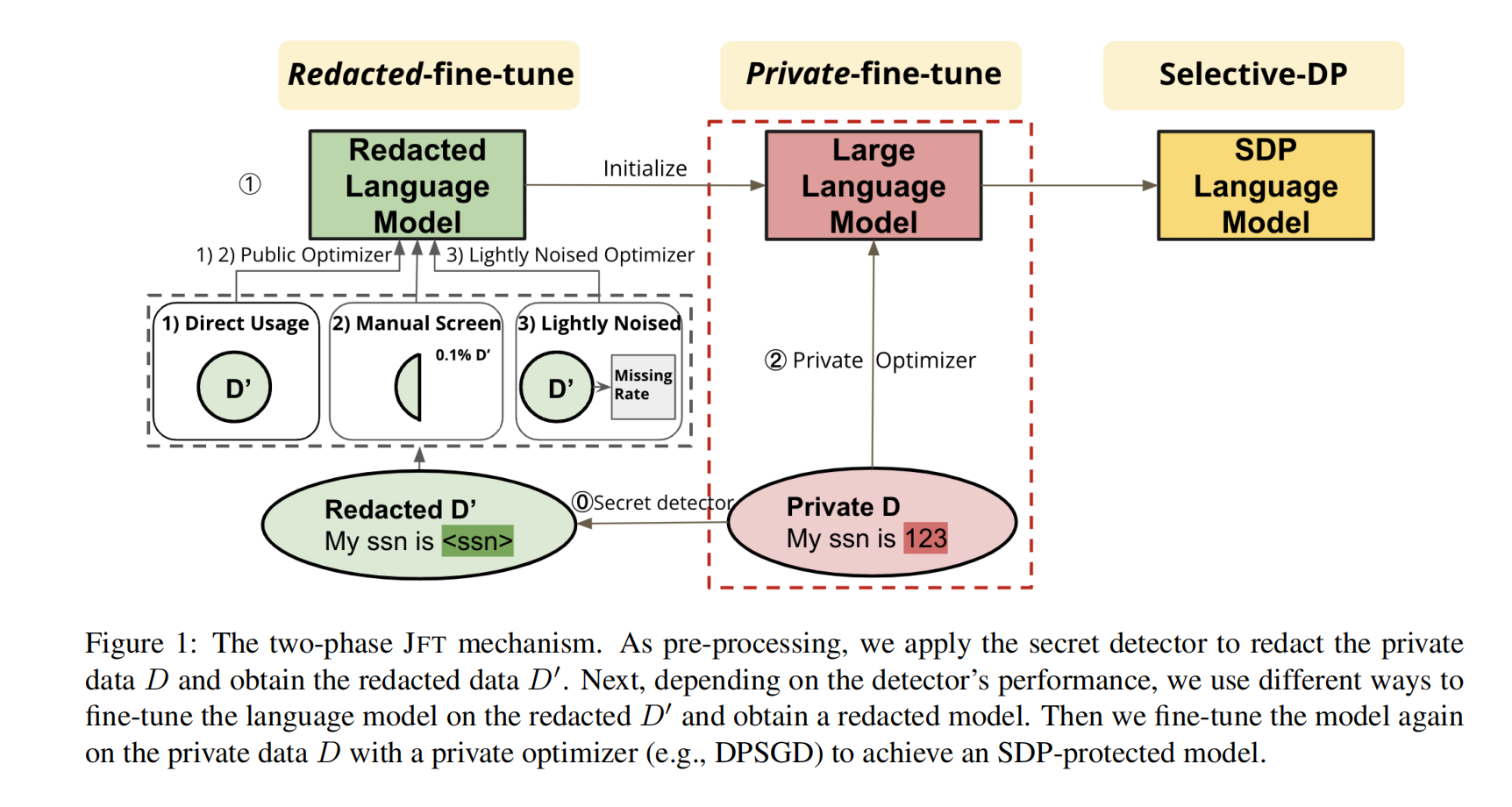
大型语言模型(LLMs)(Vaswani等,2017年)在自然语言处理领域取得了巨大的成功。它们在大量公共文本数据上进行预训练,因此擅长捕捉通用的语言结构。在NLP中,一种常见的做法是对这些LLMs进行下游任务的微调。这种微调过程在私有训练环境中也表现良好。之前,Yu等人(2021a)证明了使用私有数据,在现成的LLMs基础上额外微调一小部分参数可以达到与非私有baseline相当的性能。受到他们研究结果的启发,本文提出了一个两阶段微调隐私机制——Just fine-tune twice (JFT),以实现LLMs的SDP。我们不直接使用现成模型进行单次微调,而是采用两个微调步骤:首先我们将下游任务领域内数据进行删除,并使用这些经过删除处理后的领域内数据对模型进行微调(删除-微调),然后再对原始私有数据进行私有化微调(私有-微调)。这个额外的删除-微调步骤允许模型直接从领域内数据中学习信息,从而为第二个私有-微调步骤提供更好的模型初始化。此外,在删除-微调步骤中,我们证明即使只有有限的公共数据(可以进行手动筛选),JFT也比单次微调基准线具有更好的效用。另外,我们还可以应用轻度加噪优化器和隐私放大技术来保护未被检测到的敏感标记。
我们的贡献如下。首先,我们提出了一种有效且可推广的隐私机制,以实现大型语言模型在各种自然语言处理任务中的差分隐私保护。其次,我们设计了不同隐私级别(显式和上下文敏感数据)的秘密检测器,并研究了它们对模型的影响。第三,我们的方法可以利用少量公开数据来获得更好的效用,并通过轻度噪声优化器和隐私放大来缓解遗漏敏感token问题。最后,我们证明与常见观点相反,即隐私与效用相互冲突,在学习任务中进行差分隐私训练并不一定会损害效用,因为数据中包含的个人信息可能与学习任务无关。
==一开始想的是把论文的成果用在代码上,但这篇论文重点在于强调选择性保护。对一段代码而言,只保护一部分是否有意义?暂时想到的是保护一部分可能就可以达到保护全部的效果。这样甚至不需要这篇文章里面的策略函数了……==
邻近关系捕捉了被保护的内容。传统的差分隐私文献认为,邻近数据集是指在一个训练样本上有所不同;因此,相应的差分隐私保护整个训练样本。我们用
本文将重点设计学习算法来实现SDP。形式上,SDP依赖于策略函数
A policy function
根据策略函数在大规模语料库中手动检测私人信息往往代价高昂。在这种情况下,可以建立自动的秘密检测器来识别敏感属性。一个简单的秘密检测器示例是使用正则表达式捕获电话号码。然而,秘密检测器可能会漏掉一些私人属性并产生假阴性,直观上会削弱隐私保证。现有研究(Doudalis等,2017;Shi等,2021;Zhao等,2022)选择性地保护数据要么假设存在完美的检测器,要么使用过于保守的低假阴性但高假阳性的检测器。本文提供了解决这个问题的替代方法,并实现更好的隐私-效用权衡(第3节)。
SDP通过F定义了
那个抽象定义又长又没用,直接看底下的举例。
根据定义,包含“My ID is 123”的数据集和包含“My ID is 456”的数据集是
现在我们描述JFT,这是一个两阶段的隐私机制,用于实现大型语言模型的SDP。在第一阶段中,我们使用秘密检测器对私有数据
Direct Usage 如果秘密检测器屏蔽了
Selective Manual Screening 如果秘密检测器不完善,我们可以从
Lightly-Noised Fine-tuning 当探测器存在缺陷时,除了手动筛选出被错过的敏感信息之外,我们还可以使用私有优化器对包含被错过敏感标记的
请注意,PAS的应用要求任何批次中出现的错过标记数量相同,但这并不一定成立。因此,从隐私放大计算得出的隐私参数是对实际隐私损失的经验估计。在实践中,秘密检测器的缺失率是未知的,我们需要进行估计(表示为
在第二阶段中,我们使用来自第一阶段的已编辑模型进行初始化,并使用原始私有数据D和私有优化器(例如DPSGD(Abadi等人,2016)或任何其他实现差分隐私的更高级私有优化器)对其进行微调。与Shi等人(2021)中的隐私机制不同,我们的算法不需要了解模型或任务的知识,因此可以轻松应用于不同的模型,如GPT2(Radford等人,2019)和Roberta(Liu等人,2019),以及不同的任务,如语言生成和自然语言理解。更多实施细节请参见A.2节。
与传统差分隐私训练相比,我们的算法引入了一个额外阶段,在该阶段上进行了数据编辑和常规非加噪训练。事实上,额外阶段的计算成本远低于DP学习最初产生的成本,因为额外的第一阶段不需要昂贵的逐样本梯度剪辑和加噪操作。而且数据编辑是一种常见且熟悉的首步操作。此外还存在大量现成工具可供批量进行数据编辑。

用一张图来解释。使用现成的实体识别工具来检测文字中的敏感信息。
我们在两个自然语言处理(NLP)任务上进行实验:1)自然语言理解(NLU,在GLUE数据集上)和2)语言生成(在Wikitext-2和ABCD数据集上)。
Datasets 1)GLUE(Wang等,2018)是一个广泛使用的多任务基准数据集,用于NLU任务。它包含了一些敏感信息,如姓名和日期。2)Wikitext-2(Merity等,2017)包含了带有私人信息(如姓名和日期)的维基百科文章。3)ABCD(Chen等,2021)是一个人类-人类的客户服务对话数据集,在真实场景下收集,其中包含用户的私人信息,如姓名和订单编号。
Models 我们在NLU分类任务中使用Roberta(Liu等,2019),在语言生成任务中使用GPT2(Radford等,2019)。由于计算限制,我们在实验中使用Roberta-base和GPT2-small。我们在实现中使用了Li等人(2021)中的高效DPSGD(差分隐私随机梯度下降)方法。根据先前的研究(Li等,2021;Yu等,2021a),更大的DP模型通常可以取得更好的结果,因此我们预期更大的SDP模型将获得更好的性能。
Baselines 1)No-DP:模型使用常规的Adam优化器(Kingma和Ba,2014)进行微调,没有额外的噪声,因此没有任何隐私保证(即<MASK>标记之间不可区分,因此其隐私参数不能直接与SDP进行比较。因此,我们对CRT和SDP添加相同数量的噪声,在图2和3中通过金丝雀插入攻击进行经验比较SDP和CRT,并在附录的表6中报告效用。4)Redacted:我们还展示了Redacted模型的效用,因为它们也是隐私保护的。请注意,当秘密检测器完美时,已消除模型具有完美的SDP隐私保证(即
Our Models 1)JFT:这是我们的JFT模型,直接在第一阶段使用已消除的数据。2)JFT +手动筛选:这是JFT,使用已消除数据的子集,在第一阶段手动过滤掉遗漏的秘密信息。3)JFT +轻噪声:这是JFT,在第一阶段根据估计的遗漏率添加轻微噪声。
我们展示了三个主要发现:1)秘密检测器对结果为JFT模型的影响取决于任务,但即使对于保守的上下文检测器(30%以上的标记被删除),JFT仍然比天真的DPSGD获得更好的结果(第6.1节);2)尽管规模较小,使用手动筛选过的领域内数据仍然提高了JFT模型的效用(第6.2节);3)轻微加噪优化器与隐私放大可以保护免受攻击的敏感标记(第6.3节)。隐私和效用之间总是存在权衡,因此较大的epsilon值会带来更好的效用但更差的隐私。在比较模型时,我们需要考虑在相似隐私预算下模型效用。各种隐私文献中通常使用1到3作为epsilon值(Yu等人,2021a; Li等人,2021; Zhao等人,2022)。在我们的实验中,我们预先计算了隐私参数,在训练结束时花费约为3个epsilon。
在本文中,我们提出了JFT,它可以实现大型语言模型的选择性差分隐私。我们还设计了通用的秘密检测器,以在不同层面上提供保护,并研究其对结果SDP模型的影响,并通过选择性手动筛选和减少噪声进行私人训练来解决错过敏感标记的问题,这是由于隐私放大效应所证明的。结果表明,所提出的JFT生成具有强大性能且对金丝雀插入攻击具有鲁棒性的SDP模型。
其实读完全文还是感觉有点玄:这个微调两次居然就可以提高准确率?就是6.1节中的这段:
此外,如果JFT能够改进被编辑过的模型,则取决于任务。对于情感分析中的SST-2任务来说,私有微调步骤并不能改善被编辑过的模型。这是因为被编辑过的模型已经达到了很高的准确率(即使最差的准确率也有91.86,仅比94.8的公共模型下降了2.94),而在带有噪声梯度的私有数据上进行微调并不足以弥合这个小差距。但是对于存在较大差距(例如MNLI、QQP和QNLI) 的任务来说,JFT可以进一步改善被编辑过的模型。此外,随着隐私级别增加,被编辑模型与相应JFT模型之间的差距也变得更大:对于QNLI(低语境),差距为87.99-85.30=2.69;而对于QNLI(高语境),差距为87.06-82.81=4.25。这表明在私有微调步骤中,该模型确实从敏感标记中学习到了有效信息。
我觉得他消融实验没做完,感觉并没有排除是因为微调了两次才导致效果变好的,他应该重复做两次phase1或者重复做两次phase2,要不然感觉说服力还是不强。
别的方面暂时就是觉得挺有意思的,如果说想用到代码领域可以想个办法和AST结合,但提前预感这么麻烦的方法效果不会很好……
还有一点就是全文都没讲到底是怎么fine-tune的模型,看了代码才看出来可能是lora。